CQRS 방법론 정리1 (2025.05 ~ 2025.12)
목차
1. CQRS 개념 정리
1.1 CQRS 들어가기 전에
중간 테이블의 이점
- 주문 시 상품 정보를 중복 작성할 필요 없음
- 중간 테이블만 업데이트하면 됨
- 상품 정보 변경 시 전체 업데이트 불필요
인덱스 사용 범용성
- RDBMS의 B-Tree 기반 인덱스
- Embedded Index
- 검색 엔진에서의 인덱스
- RDBMS 벡터 검색: 벡터 데이터 형변환 시 무거운 벡터 오퍼레이션을 CQRS로 적용
1.2 이벤트 드리븐 방식: 인과적 일관성
연쇄적 상태 변경
- 하나의 트랜잭션이 아닌 경우 상태 업데이트 과정을 느슨하게 분리
- ⚠️ 주의: 주문 수량 변경은 이벤트로 개발하면 안 됨
- ✅ 가능: 결제 상태 변경은 이벤트 드리븐 방식 적용 가능
1.3 CQRS의 기술 이점
장점
- DB를 목적에 맞게 분리하여 성능 최적화 가능
- 읽기 부하 감소: 100의 쿼리 부하 → 90으로 감소 가능
- 주로 읽기가 많은 경우에 효과적
단점 및 Trade-Off
- DB 사용 분리로 인한 코드 복잡성 증가
- Command 데이터 모델 변경 시 Query 데이터 모델도 함께 변경 필요
- 커맨드에서의 부하보다 쿼리의 부하가 압도적으로 높음
1.4 CQRS 구현 단계
1단계: 코드 수준 분리
- 메서드로 Query와 Command 분리
2단계: 모델 분리
- 같은 DB 내에서 역할에 맞는 모델 분리
- 상품정보, 가격, 카테고리 등을 모은 통합 모델 생성
3단계: 저장소 수준 분리 (CQS)
- 비즈니스 모델의 특성에 따라 DB 선택
- DB까지 분리해야 최종적인 CQRS 완성
1.5 동기화 방식
비동기식 업데이트
- 커맨드 모델 변경 → 이벤트 큐 → 쿼리 모델 업데이트
- 네트워크 문제로 인한 최종 일관성 보장 복잡
- 지연 시간 발생 가능
동기식 업데이트
- 즉시 반영
- 성능 저하 가능성
1.6 일관성 전략
강한 일관성
- 결제, 예약 시스템, 재고 시스템에 적용
- 성능적으로 불리하나 중요한 비즈니스에 필수
인과적 일관성
- 게시글 작성 시 작성자에게는 즉시 표시
- 다른 사용자에게는 지연 허용
최종 일관성
- 상품 등록 후 몇백ms 후 목록 반영
- 성능적으로 유리
1.7 추가 참고사항
응답 시간 기준
- 현업에서는 일반적으로 100~200ms 정도로 응답 시간 측정
관계 구조
- 주문-상품 관계에서 주문이 메인이므로 주문 입장에서는 1:N 구조
2. 실생활 적용 시스템 아키텍처
2.1 소셜 미디어 피드 시스템
온디맨드 조회 방식의 문제점
성능 문제
- 대량 JOIN 연산
- N+1 문제 발생
- 네트워크 라운드 트립 증가로 인한 성능 하락
- 카디널리티 익스플로젼: 수천 명 팔로우 시 JOIN 연산 비용 급증
사용자 경험 저하
- 느린 피드 로딩 시간
- 사용자 기반 확대 시 DB 성능 문제 심화
해결 방안: 미리 계산된 피드
Kafka를 통한 이벤트 전파
- 상태 변경 이벤트 전파
- 미리 계산된 피드에서 쿼리 모델 사용
Fan-Out 전략 최적화
| 전략 | 대상 | 저장소 | 특징 |
|---|---|---|---|
| Fan-out-on-Write | 일반 사용자 | RDBMS | 팔로워가 적은 경우, 게시글 즉시 배포(저장) |
| Fan-out-on-Read | 인플루언서 | NoSQL | 팔로워가 많은 경우, 게시글을 요청 시 병합 (Hotspot 레코드) |
최종 피드 생성
- 두 조회 결과를 병합하여 사용자 피드에 표시
NoSQL 최적화 기법
키 설계
- 파티션 키
- 클러스터링 키: 시간순 정렬 저장으로 범위 쿼리 최적화
- 복합 프라이머리 키로 페이지네이션 효율화
데이터 모델링
- 비정규화로 조인 없이 조회 가능
아키텍처 구성
동기화 방식
- 비동기 Kafka를 이용한 동기화
2.2 커머스 플랫폼의 상품 관리/검색 시스템
핵심 개념
모델 동기화 컴포넌트
- Elasticsearch 활용
멱등성
- 몇 번을 조회하더라도 일관성 제공 및 보장
이벤트 발행
- Kafka에 이벤트 발행
- CDC(Change Data Capture) 개념 이용
- Debezium 커넥터 활용
검색 모델 구성
반정규화 모델
- 정규화된 테이블들을 반정규화된 모델로 구성
- 하나의 통합 문서로 검색 및 필터링 수행
멀티필드 인덱스
- 복합 필드 필터링을 통한 빠른 결과 도출
- 역색인(Inverted Index) 활용
검색 인덱스 업데이트
데이터 인덱싱
- 변환된 데이터를 Elasticsearch에 인덱싱(저장)
- 벌크 연산으로 성능 최적화
- 네트워크 라운드 트립 감소
- Kafka Consumer에서 특정 양을 한 번에 가져와 효율적으로 업데이트
커머스 플랫폼 CQRS 아키텍처
커맨드 모델
PostgreSQL → WAL 로그 작성 → 데이터 업데이트
↓
CDC가 WAL 로그 읽기
↓
Kafka에 발행
↓
검색 엔진 인덱서가 Elasticsearch에 인덱싱
쿼리 모델
- Elasticsearch에서 데이터 조회
- 필요 시 RDBMS에서도 데이터 조회 가능
2.3 점진적 도입을 위한 단계별 접근법
1단계
- 코드 단계에서 메서드 분리
2단계
- 반정규화 모델로 변경
3단계
- 저장소 분리 및 CDC 적용
Kafka 사용 이유
- 실패 시에도 리텐션이 길어 액션 리플레이 가능
- 복구 용이
2.4 실제 도입 시 고려사항
CDC vs 직접 이벤트 발행
| 방식 | 특징 | 장점 | 단점 |
|---|---|---|---|
| CDC (Debezium, DMS 등) | 테이블 단위 동기화 | 자동화된 변경 감지 | 원하지 않는 형태일 수 있음 |
| 직접 이벤트 발행 | 커스텀 이벤트 | 원하는 쿼리 데이터 전송 가능 | 개발 복잡도 증가 |
주의사항
- 읽기 작업에 적합
- 팀의 인프라 기술 수준 고려 필요
- CRUD 작업에 과도한 적용 피하기
- 동기화 문제 과소평가 금지
- 모니터링 필수
3. 이벤트 기반 아키텍처
3.1 동기화 방식 비교
1) 동기식 모델 동기화
- DB 모델과 서버 컴포넌트가 2개 이상으로 분리
- 쿼리 모델 장애가 커맨드 모델 장애로 전파
2) 비동기 모델 동기화 1
커맨드 모델 업데이트
↓
이벤트 큐에 이벤트 발행
↓
모델 동기화 컴포넌트가 구독
↓
쿼리 모델 업데이트
3) 비동기 모델 동기화 2 (CDC 방식)
CDC가 변경 감지
↓
변경 전/후 데이터를 이벤트 큐에 발행
↓
모델 동기화
특징
- 테이블 단위 기준
- 쿼리 모델이 원하는 형태여야 함 (커스텀 필요)
- 모델 동기화 부분의 코드 복잡도 증가 가능
아웃박스 패턴(Outbox Pattern)
- 쿼리 모델을 손쉽게 업데이트 가능
- 하나의 모델 업데이트를 위해 여러 모델을 조합해야 하는 경우 유용
- 히스토리를 차곡차곡 쌓아 다른 곳에서도 재사용 가능
- ⚠️ 주의: 아웃박스 테이블 쓰기 비용 발생
4) 비동기식 모델 동기화의 장점
느슨한 결합
- 커맨드 모델과 쿼리 모델 사이에 모델 동기화 컴포넌트 존재
- 직접 결합 방지
장점
- 이벤트 큐에 의한 장애 격리
- 이벤트 스트림 재사용 가능
- 다른 모델 초기화에 활용
단점
- 복잡한 오류 처리/재시도 메커니즘 필요
- 디버깅과 모니터링 난이도 상승
3.2 트랜잭션 관리
서비스 레이어 트랜잭션
- 서비스 레이어에서 트랜잭션이 걸려 있으면 DB 업데이트까지 트랜잭션 적용
- 아웃박스 테이블 업데이트와 커맨드 모델 업데이트를 함께 트랜잭션 처리하는 것이 일반적
- 비즈니스 가치에 따라 달라질 수 있음
CDC 대안
- 필요 없으면 생략 가능
- 애플리케이션에서 직접 폴링 방식으로 이벤트 관찰 구현 가능
3.3 이벤트 스키마 관리
이벤트 스키마 포맷
1) AVRO
- Confluent Schema Registry가 Kafka와 자주 사용됨
- 생태계 최적화
2) ProtoBuf
- gRPC에 익숙한 경우 권장
스키마 설계 및 버전 관리
호환성 유지 원칙
후방 호환성
- 이벤트 삭제 또는 필수 필드 추가 시 쿼리 모델 수정 필요
- 쿼리 모델이 이해할 수 없는 이벤트 처리 전략
- Unknown Event 핸들러 구현 (Logging, Alert 포함)
- 미처리 이벤트 큐 보관
- 쿼리 모델 업데이트 후 재처리
고려사항
- 시간에 대한 기록이 남아 있어 모델 변경 시 이미 발행된 쿼리 모델도 업데이트 필요
스키마 레지스트리
| 솔루션 | 라이선스 |
|---|---|
| Karapace | 무료 |
| Apicurio | 무료 |
| Confluent Schema Registry | 유료 |
4. Kafka 개념 및 실습
4.1 Kafka 동작 방식
1. 프로듀서가 이벤트 발행
2. 파티션에 이벤트(메시지) 저장
- 같은 파티션 내 이벤트만 순서 보장
3. 파티션 레플리카로 가용성 확보
4. 파티션에 쌓인 이벤트가 순서대로 처리 및 전달
5. 파티션에서 복구 진행
6. 컨슈머들이 독립적으로 이벤트 소비
7. 각 컨슈머는 독립적인 offset 관리
8. 프로듀서가 파티션 결정
9. 컨슈머 리밸런싱으로 이벤트 재분배
10. 이벤트가 디스크에 반영구적으로 저장
4.2 Kafka 메시지 구조
Key 섹션
- 순서가 필요한 경우 비즈니스별로 담음
- 엔티티 ID 기반 파티셔닝
Header 섹션
- 이벤트의 메타데이터 전송
Value 섹션
- 비즈니스 데이터(바디 데이터)
4.3 파티션 관리
파티션 불균형(Skew) 관리
- 트래픽 집중 현상 방지
- 복합 키 사용 가능 (핫 키 + 유니크 키)
순서 보장
- 시간 순서 보장이 필요한 이벤트는 같은 파티션에 저장
- 파티셔너는 해싱을 통해 같은 키 값을 같은 파티션에 배치
4.4 컨슈머 그룹 관리
기본 원리
- 파티셔너는 컨슈머 그룹을 확인하지 않음
- 컨슈머 그룹별로 이벤트를 독립적으로 소비
파티션과 컨슈머 수
- 파티션이 3개, 컨슈머가 4개인 경우 → 1개의 컨슈머는 유휴 상태
4.5 오류 처리 및 모니터링
실패한 이벤트 처리
- 실패 메시지 무시 옵션
- Dead Letter Queue(DLQ)에 실패 메시지 수집 후 순차 처리
멱등성의 중요성
- 네트워크 등의 문제로 에러 발생 시 해당 오프셋부터 재처리
- 중복 처리되어도 결과가 동일하도록 보장
- 작업 완료 후 커밋되지 않은 오프셋도 멱등성으로 안전하게 처리
모니터링
- Kafka Admin에서 파티션별 오프셋 정보 확인
- 최신 모델과 현재 오프셋 차이로 지연 확인
- 커맨드 모델 변경 후 쿼리 모델 반영까지의 시간 측정
4.6 CDC 무중단 도입 전략
문제 상황
- 기존 서비스에 CDC를 무중단으로 도입
- 최초 1회 데이터 동기화 필요
- 운영 서비스는 중단 불가
- 전체 데이터 복사 중에도 쓰기 트래픽 발생
해결 방안
- 기존 DB 풀스캔 시작
- 변경/추가 이력은 CDC에 자동 기록
- 풀스캔 완료 후 Kafka 동기화가 최신 오프셋부터 재스캔
- 최신 오프셋 비교를 통해 동기화 완료 판단
도구
- Flinker를 활용한 병렬 읽기 및 적재
5. Debezium 프로젝트 실습
5.1 Docker Compose 설정
# Kafka - 메시지 브로커
kafka:
image: confluentinc/cp-kafka:7.9.0
container_name: kafka
depends_on:
- zookeeper
ports:
- "9092:9092"
- "29092:29092"
volumes:
- kafka_data:/var/lib/kafka/data
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka:9092,PLAINTEXT_HOST://localhost:29092
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1
# 토픽 자동 생성 설정
KAFKA_AUTO_CREATE_TOPICS_ENABLE: true
5.2 자동 토픽 생성 설정
KAFKA_AUTO_CREATE_TOPICS_ENABLE: true 필요 이유
Debezium은 CDC를 통해 데이터베이스 변경 사항을 Kafka 토픽으로 전송합니다.
Debezium 커넥터가 자동 생성하는 토픽
dbserver1.inventory.products(각 테이블 단위 토픽)dbserver1.inventory._schema(스키마 메타데이터 저장용)dbserver1.inventory._transaction(트랜잭션 로그용)
설정 미적용 시
auto.create.topics.enable=false상태에서는 토픽이 존재하지 않아 오류 발생- CDC가 시작되지 않음
5.3 Debezium 커넥터 설정
테이블 포함 목록 설정
"table.include.list": "public.products,public.product_prices,public.product_categories,public.product_tags,public.product_details,public.reviews,public.product_option_groups"
메시지 키 매핑 설정
ID 값 변환 처리
- Debezium에서는 커넥터의 ID 값 변환을 수동으로 설정 필요
idvsproductId호환성 문제 해결
"message.key.columns": "public.products:id;public.product_prices:product_id;public.product_categories:product_id;public.product_tags:product_id;public.product_details:product_id;public.reviews:product_id;public.product_option_groups:product_id",
"transforms": "RenameProductKey,RouteByTable",
"transforms.RenameProductKey.type": "org.apache.kafka.connect.transforms.ReplaceField$Key",
"transforms.RenameProductKey.renames": "id:product_id",
"transforms.RenameProductKey.predicate": "isProducts",
"transforms.RouteByTable.type": "org.apache.kafka.connect.transforms.RegexRouter",
"transforms.RouteByTable.regex": "product.public.(.*)",
"transforms.RouteByTable.replacement": "product-events",
"predicates": "isProducts",
"predicates.isProducts.type": "org.apache.kafka.connect.transforms.predicates.TopicNameMatches",
"predicates.isProducts.pattern": ".*products$"
AWS DMS 대안
- AWS의 관리형 서비스인 AWS DMS 사용 시 ID 값 변환이 더 손쉽게 제공됨
특수 케이스 처리
ProductOption 테이블
- ProductOptionGroup에만 productId 존재
- 직접적인 productId 참조 없음
- 스키마 변경하지 않는 경우 대비 필요
5.4 커넥터 등록 스크립트
# Product 커넥터 등록
curl -X POST -H "Content-Type: application/json" \
--data @postgres-product-connector.json \
http://localhost:8083/connectors
# Option/Image 커넥터 등록
curl -X POST -H "Content-Type: application/json" \
--data @postgres-product-option-connector.json \
http://localhost:8083/connectors
# Category 커넥터 등록
curl -X POST -H "Content-Type: application/json" \
--data @postgres-category-connector.json \
http://localhost:8083/connectors
# Brand 커넥터 등록
curl -X POST -H "Content-Type: application/json" \
--data @postgres-brand-connector.json \
http://localhost:8083/connectors
# Seller 커넥터 등록
curl -X POST -H "Content-Type: application/json" \
--data @postgres-seller-connector.json \
http://localhost:8083/connectors
# Tag 커넥터 등록
curl -X POST -H "Content-Type: application/json" \
--data @postgres-tag-connector.json \
http://localhost:8083/connectors
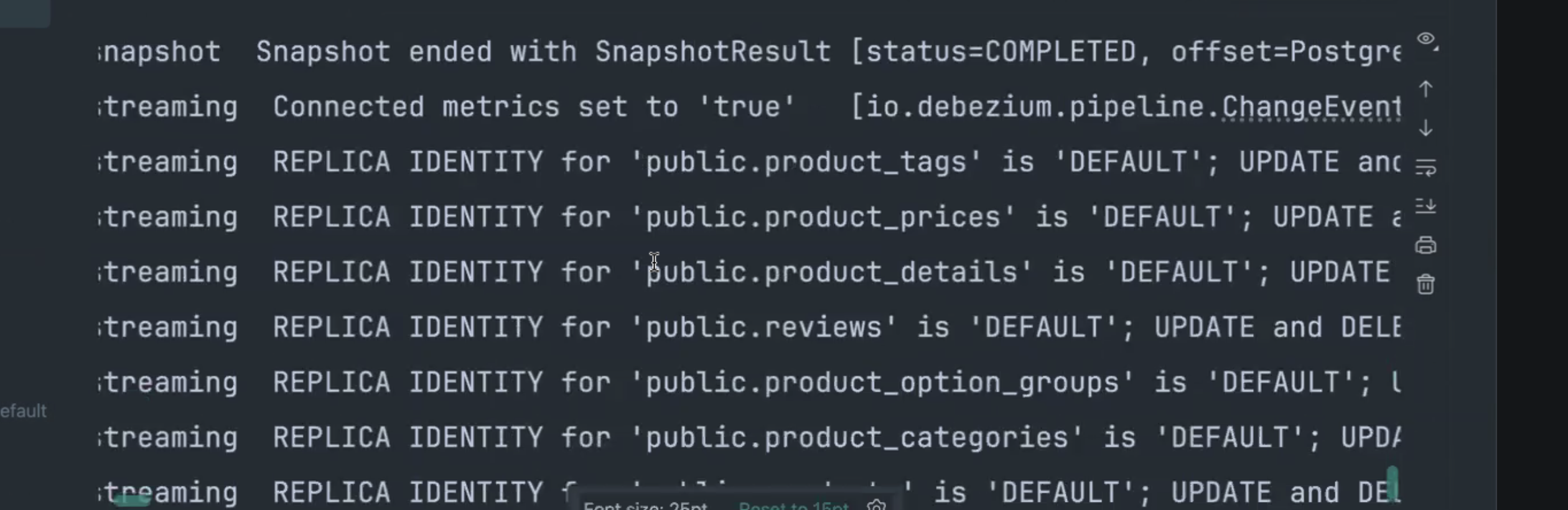
5.5 토픽 이름 커스터마이징
"transforms.RouteByTable.replacement": "product-events"
위 설정으로 모든 변경 이벤트를 product-events 토픽으로 라우팅할 수 있습니다.
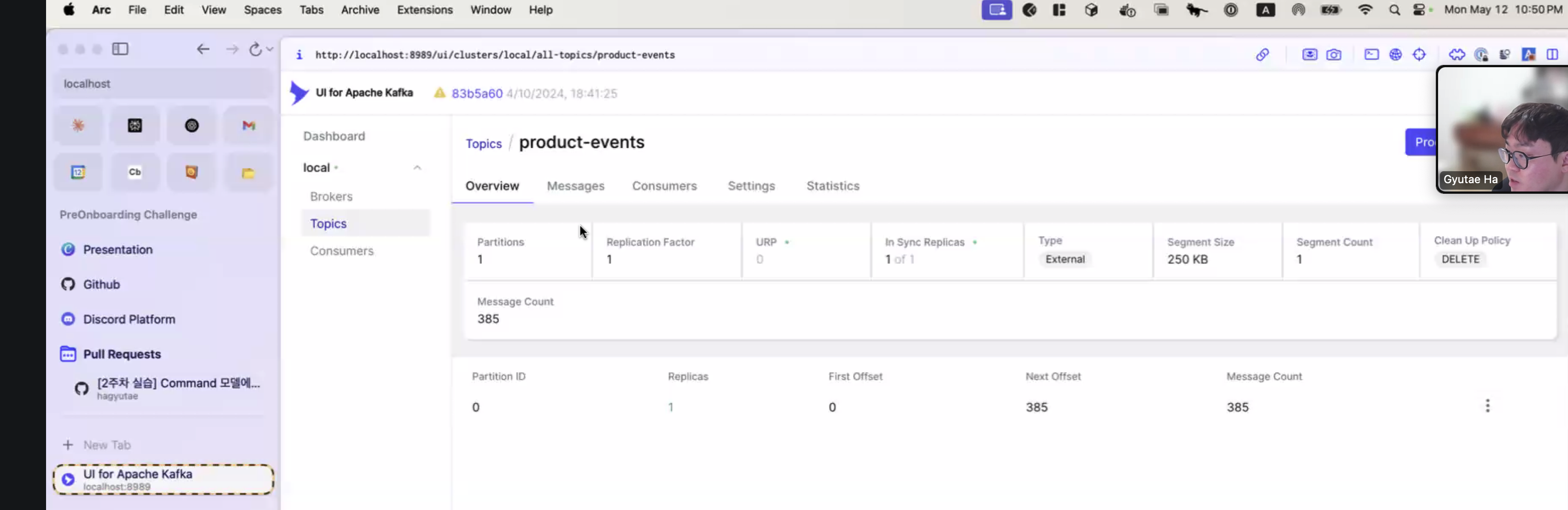
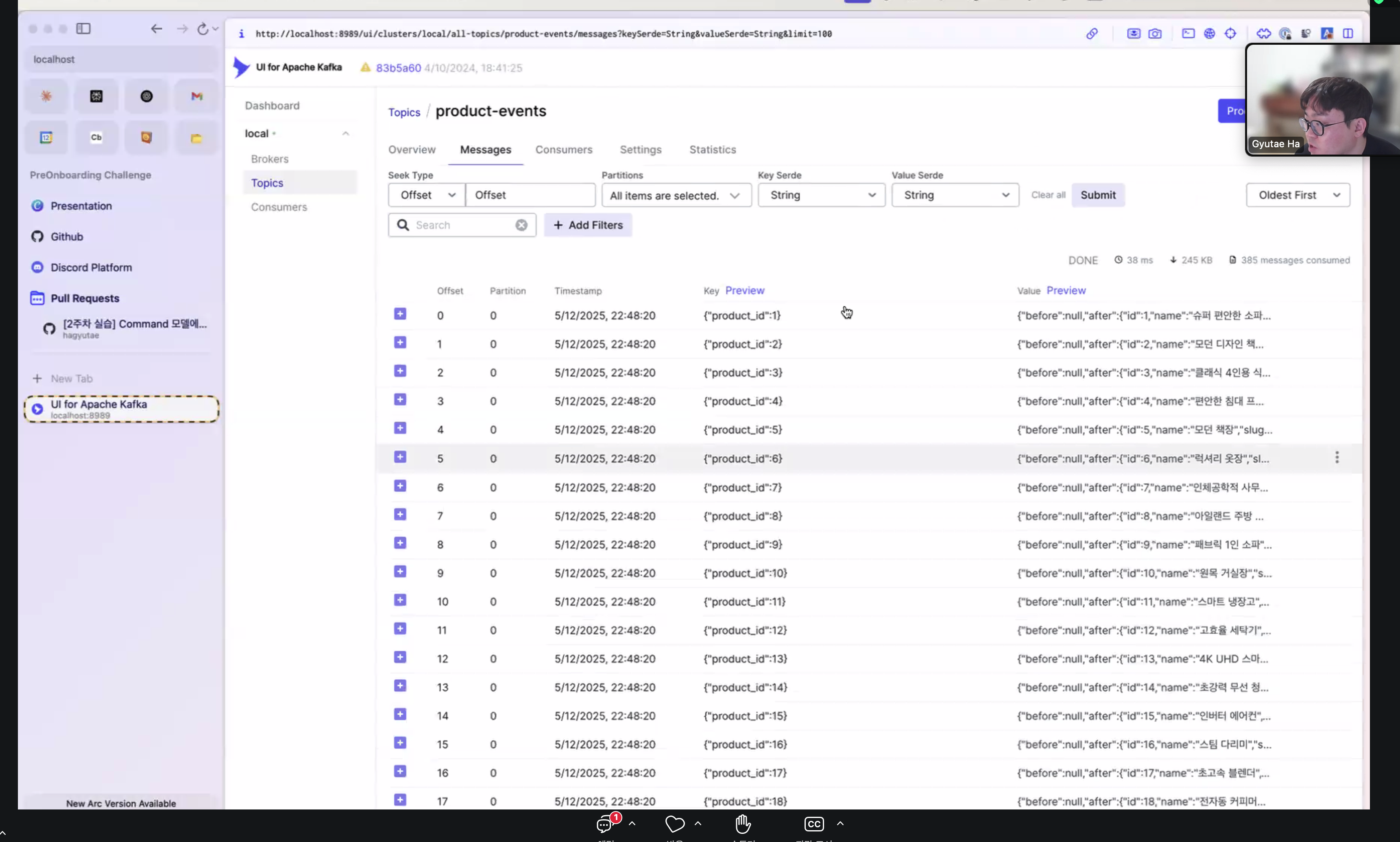
5.6 Kafka UI에서 확인
확인 방법
- Kafka UI의 라이브 모드에서 실시간 확인
- 동일 파티션으로 전송 확인
- 토픽에서 변경 내용 확인
참고사항
이 문서는 CQRS 강의 내용을 기반으로 작성되었으며, 실무 적용 시 프로젝트의 특성과 요구사항에 맞게 조정하여 사용해야 합니다.
주요 참고 자료
- Debezium 공식 문서
- Confluent Kafka 문서
- Elasticsearch 공식 문서
- AWS DMS 문서