CQRS 방법론 정리2 (2025.05 ~ 2025.12)
목차
6. 다중 데이터 저장소 전략
6.1 다중 데이터 저장소의 목적
성능 최적화를 위한 전략
- 같은 네트워크 내에서는 I/O 지연이 적음
- 각 DB의 특성에 맞는 데이터 저장
조회 시간 기준
- 전체 조회 시간: 150~200ms 이내 권장
- Elasticsearch + MongoDB + Redis 조합 활용
사용 예시
- 재고 데이터: Redis 캐싱으로 수십 ms 내 조회 가능
- 검색 필터링: Elasticsearch
- 원본 문서 조회: MongoDB
6.2 백엔드 개발 트렌드
DB 선택 시 고려사항
- DB의 자료구조 이해 필수
- 해당 DB 특성상 최적화 과정 파악
- 해결하고자 하는 문제에 적합한 오퍼레이션 확인
6.3 벡터 DB 고려사항
Elasticsearch의 한계
- 대량의 벡터 데이터 인덱싱 시 안정성 부족
- 벡터 기반 검색에는 전용 DB 사용 권장 (예: Qdrant)
벡터 DB 특성
- 차원 간 전환 시 부하 발생
- 성능 최적화가 중요
6.4 Elasticsearch vs MongoDB
Elasticsearch 특성
작동 원리
- 역색인(Inverted Index) 개념 사용
- 문서 ID를 여러 개 엮어서 조건에 맞는 연산 수행
- 결과 도출은 매우 빠름
장단점
| 작업 유형 | 속도 |
|---|---|
| 필터링 및 검색 | 매우 빠름 ⚡ |
| 문서 ID 찾기 | 매우 빠름 ⚡ |
| 개별 문서 원본 조회 | 느림 🐢 |
사용 권장 케이스
- 초기 시스템에서 원본 데이터가 적은 경우
- 필터링이 주된 목적인 경우
MongoDB 특성
작동 원리
- B+Tree 구조
- 원본 문서를 찾는 속도가 매우 빠름
장점
- 개별 문서 조회 성능 우수
- 문서 지향 데이터베이스
6.5 I/O 최적화 전략
네트워크 라운드 트립 고려
- 데이터가 적은 경우: Elasticsearch 단일 조회 (1번의 라운드 트립)
- 데이터가 많은 경우: Elasticsearch + MongoDB 조합 (2번의 라운드 트립)
결론
- 비즈니스 특성에 맞는 다중 저장소 설계가 중요
7. 실습 코드 분석
7.1 모델 부분
스키마 관리
inStock과 같은 비즈니스 필드 변경 시 스키마 업데이트- 이벤트 스키마 무중단 교체 수행
성능 최적화 원칙
- ❌ 쿼리 시점에 계산 금지
- ✅ 커맨드 실행 시 계산하여 미리 DB에 저장
필드 설계 예시
inStock: 재고 확인용 불린 필드- 상세 수량 체크가 필요한 경우 별도 처리
데이터 모델링 전략
- Product와 직접 관련 있는 내용은 반정규화
- 참조 전략으로 JOIN 사용
7.2 비즈니스 및 서비스 부분
주요 컴포넌트
ProductDocumentOperations
- MongoDB 문서 연산 처리
QueryService
- Elasticsearch와 MongoDB 검색 구현
- 캐싱 전략 적용
캐싱 전략
- 단일 검색 결과 캐싱
getProduct와 같은 단일 객체 조회 시 캐싱
CDC 이벤트 처리
cdcEvent 구조
before: 변경 전 데이터after: 변경 후 데이터source: 테이블 정보
핸들러 구조
Document 핸들러
- MongoDB용 이벤트 핸들러 모음
Search 핸들러
- Elasticsearch용 이벤트 핸들러 모음
- SME (SearchModelEvent) 처리
ProductSearchModelSyncer
- 이벤트 핸들러 통합 관리
- 큐에서 이벤트 처리 가능 여부 체크
- 모델 업데이트 수행
7.3 디버깅 방법
브레이크 포인트 활용
- 개별 이벤트 처리 과정 파악
- 데이터 흐름 추적
시스템 도식화
- 손으로 직접 시스템 구조 그리기
- 참고 URL: https://app.excalidraw.com/l/zZ6L7Mz24A/8DJ2xINRMER
8. 실습 환경 구성
8.1 초기 서버 설정 순서
권장 브랜치
- 2번째 브랜치 사용 권장
- 브랜치 이동 시 설정 변경으로 에러 발생 가능
- 각 폴더에서 개별 클론 권장
실행 순서
- DDL 파일 실행 (테이블 생성 및 데이터 INSERT)
- docker-compose.yml에서 자동 실행 설정 가능
- docker-compose.yml 실행
- register.sh 실행 (Debezium CDC 커넥터 등록)
- 톰캣 서버 시작
- Kafka UI에서 이벤트 라이브 모드 확인 (선택)
- API 테스트
포트 정보
- HTTP API: localhost:8080
- Kafka UI: localhost:8989
8.2 성능 특성
병렬 처리 효과
- INSERT 시 관련 테이블 개수만큼 이벤트 큐 생성
- 병렬 처리로 처리 시간 감소
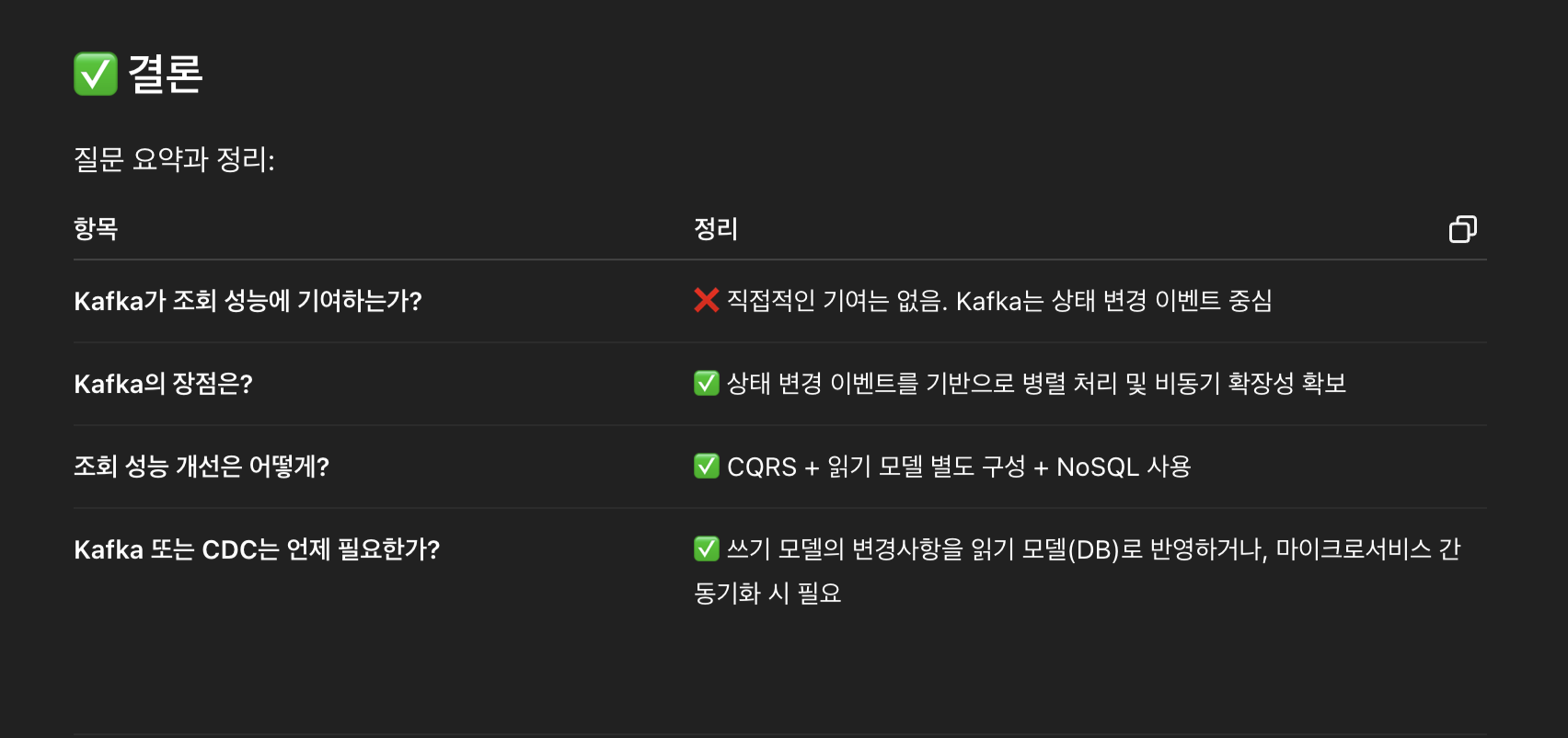
CQRS의 성능 이점
- 조회 쿼리: 성능 향상 효과 제한적
- 상태 변경(INSERT, DELETE, UPDATE): 병렬 처리로 성능 향상
- DB를 요구사항에 따라 분리할 때 Kafka/CDC 필요
아키텍처 원칙
| 개념 | 설명 |
|---|---|
| CQRS | Command와 Query 책임 분리 |
| 이벤트 기반 아키텍처 | 비동기 이벤트 처리 |
| Polyglot Persistence | 다중 DB 전략 |
| CDC | 변경 데이터 캡처 |
9. Kafka 개발 환경 이슈 해결
9.1 Cluster ID 불일치 에러
에러 메시지
Invalid cluster.id in: /var/lib/kafka/data/meta.properties
Expected E-G5GZXETG2XFSGwGaxGKQ, but read CX4OIZCKQ9-v0eXstX4ubA
발생 원인
- Zookeeper에 등록된 Cluster ID:
E-G5GZXETG2XFSGwGaxGKQ - Kafka 볼륨의 Cluster ID:
CX4OIZCKQ9-v0eXstX4ubA - 두 ID가 불일치하여 Kafka가 시작 거부
왜 발생하는가?
- Kafka는 브로커 초기화 시 cluster.id 고정
- Zookeeper와 Kafka 데이터 디렉터리의 cluster.id 비교
- 불일치 시 데이터 보호를 위해 즉시 종료
9.2 해결 방안
1️⃣ 로컬 개발 환경 (권장)
데이터 완전 초기화
# 컨테이너 중지
docker-compose down
# Kafka 데이터 볼륨 삭제
docker volume rm <kafka-volume-name>
# 바인드 마운트인 경우
rm -rf ./kafka-data
# 재실행
docker-compose up -d
2️⃣ 데이터 보존이 필요한 경우
확인 절차
# Kafka 데이터 확인
cat /var/lib/kafka/data/meta.properties
# 출력: cluster.id=CX4OIZCKQ9-v0eXstX4ubA
# Zookeeper 확인
zookeeper-shell zookeeper:2181 get /cluster/id
선택지
- ✅ Zookeeper를 Kafka 데이터에 맞게 초기화
- ❌ Kafka 데이터에 수동으로 cluster.id 수정 (비권장)
3️⃣ meta.properties 수동 수정 (비권장)
vi /var/lib/kafka/data/meta.properties
cluster.id=E-G5GZXETG2XFSGwGaxGKQ
⚠️ 주의: 운영 환경에서는 절대 비권장
4️⃣ 운영 환경 권장 아키텍처
[ Zookeeper (3 nodes) ]
|
|
[ Kafka Broker 1 ] — [ Kafka Broker 2 ] — [ Kafka Broker 3 ]
볼륨 매핑
volumes:
- /data/kafka/broker-1:/var/lib/kafka/data
- 운영에서는 docker volume ❌ / host bind mount ✅ 권장
5️⃣ 안전한 Kafka 재기동 (Rolling Restart)
올바른 절차
- Broker 1 중지
- Broker 1 기동
- ISR 정상 복귀 확인
- Broker 2 반복
- Broker 3 반복
상태 확인
kafka-topics.sh --bootstrap-server localhost:9092 --describe
# ISR에 모든 replica가 있어야 다음 브로커 진행
6️⃣ Kafka 버전 업그레이드 전략
| 단계 | 설명 |
|---|---|
| 1 | 기존 브로커 중 1대 중지 |
| 2 | 새 이미지로 교체 |
| 3 | 동일 data 디렉터리로 기동 |
| 4 | 정상 join 확인 |
| 5 | 다음 브로커 진행 |
절대 금지 사항
- ❌ 기존 데이터 디렉터리에 다른 cluster.id Kafka 실행
- ❌ 전체 브로커 동시 종료
7️⃣ Zookeeper 재구성 전략
절대 금지
- ❌ Zookeeper 전체 삭제
- ❌ Zookeeper 단일 노드 운영
- ❌ Kafka보다 먼저 삭제
안전한 방식
- Zookeeper quorum 유지
- Rolling restart
- dataDir 유지
8️⃣ KRaft 모드 (차세대 권장)
장점
| 항목 | ZK | KRaft |
|---|---|---|
| cluster.id | ZK 의존 | 자체 관리 |
| 구성 복잡도 | 높음 | 낮음 |
| 장애 포인트 | 많음 | 적음 |
| 운영 안정성 | 보통 | 높음 |
운영 기준
- Kafka 3.5+ → KRaft 적극 권장
- 신규 운영 환경이면 무조건 KRaft
9.3 분산 시스템 개발 방법론
로컬 ↔ 운영 환경 이슈
전형적인 시나리오
① 로컬 A 컴퓨터
- docker-compose up
- Kafka + Zookeeper 실행
- data 볼륨 생성 (cluster.id = A)
② docker-compose down
- 컨테이너만 종료
- 볼륨은 그대로 남음 (중요!)
③ 다른 컴퓨터 B
- docker-compose.yml 수정
(DB 추가, 네트워크 구조 변경 등)
- git commit & push
④ 다시 로컬 A 컴퓨터
- git pull
- docker-compose up
👉 이 시점에서 에러 발생
Kafka 관점에서의 동작
| 단계 | Kafka 내부 동작 |
|---|---|
| 최초 실행 | Zookeeper에 cluster.id 등록 |
| Kafka data 볼륨 | meta.properties에 cluster.id 저장 |
| compose 변경 | 서비스 구조 재조정 |
| 재기동 | Zookeeper가 “새 클러스터”로 인식 |
| 결과 | 기존 Kafka 데이터 ≠ 현재 Zookeeper |
가장 좋은 로컬 개발 전략
docker-compose 예시
services:
zookeeper:
volumes:
- zookeeper-data:/data
kafka:
volumes:
- kafka-data:/var/lib/kafka/data
volumes:
zookeeper-data:
kafka-data:
구조 변경 시
docker-compose down -v
docker-compose up -d
실무 워크플로우
추천 루틴
1. git pull
2. docker-compose down -v # 중요!
3. docker-compose up -d
상태 기반 분산 시스템의 공통 특성
| 시스템 | 동일 이슈 |
|---|---|
| Elasticsearch | cluster UUID mismatch |
| MongoDB ReplicaSet | replicaSetId mismatch |
| Redis Cluster | node-id conflict |
| etcd | member ID mismatch |
정리
로컬 개발
git pull
docker-compose down -v
docker-compose up -d
운영
- 절대
down -v금지 - Rolling restart만 허용
- 볼륨 수명 = 클러스터 수명
10. JPA 실무 가이드
10.1 JPA 연관관계 설정
단방향 설정 권장
기본 원칙
- 웬만하면 JPA 단방향 설정 사용
@xToOne영속성 관계에서 LAZY 설정 기본- 양방향 설정보다 단방향 설정 권장 (복잡성 감소)
결론
- 실무에서는 단방향 설정 우선
- 불가피한 경우에만 양방향 사용 및 신중한 관리
10.2 JPA FK 설정
설정 위치
- 주인이 아닌 자식 객체에서 FK 설정
단방향 CASCADE 설정
@ManyToOne(fetch = FetchType.LAZY)
@OnDelete(action = OnDeleteAction.CASCADE)
@JoinColumn(name = "product_id")
private Product product;
@ManyToOne(fetch = FetchType.LAZY)
@OnDelete(action = OnDeleteAction.CASCADE)
@JoinColumn(name = "tag_id")
private Tag tag;
10.3 IntelliJ Ultimate 기능
JPA Entity 자동 생성
- DB 연결
- 테이블 우클릭
Create JPA Entities From DB선택
Entity Attributes 추가
Create JPA Entities Attributes From DB- 추가된 칼럼이나 FK 칼럼 자동 생성
10.4 Fetch Join
수정 전 (N+1 문제)
private List<ProductLineEntity> getProductLineEntitiesByCategory(
Long categoryId, Pageable pageable, String keyword) {
List<OrderSpecifier<?>> orderSpecifiers = getOrderSpecifiers(pageable.getSort());
// ProductLine 3개 조회 시 Product 쿼리도 3번 추가 실행
return jpaQueryFactory
.selectDistinct(qProductLine)
.from(qProductLine)
.where(qProductLine.category.categoryId.eq(categoryId)
.and(qProductLine.deletedAt.isNull())
.and(getSearchCondition(keyword)))
.orderBy(orderSpecifiers.toArray(new OrderSpecifier[0]))
.offset(pageable.getOffset())
.limit(pageable.getPageSize() + 1)
.fetch();
}
문제점
- ProductLine 조회: 1개 쿼리
- 각 ProductLine의 Product 조회: N개 쿼리
- 총 1 + N개 쿼리 실행
수정 후 (Fetch Join 적용)
private List<ProductLineEntity> getProductLineEntitiesByCategory(
Long categoryId, Pageable pageable, String keyword) {
List<OrderSpecifier<?>> orderSpecifiers = getOrderSpecifiers(pageable.getSort());
return jpaQueryFactory
.selectDistinct(qProductLine)
.from(qProductLine)
.leftJoin(qProductLine.products, qProduct).fetchJoin()
.where(qProductLine.category.categoryId.eq(categoryId)
.and(qProductLine.deletedAt.isNull())
.and(getSearchCondition(keyword)))
.orderBy(orderSpecifiers.toArray(new OrderSpecifier[0]))
.offset(pageable.getOffset())
.limit(pageable.getPageSize() + 1)
.fetch();
}
개선점
- 쿼리 4개 → 1개로 감소
- ProductLine과 Product를 한 번에 조회
10.5 Fetch Join 사용 시 문제점
A. 메모리 문제
증상
- SQL LIMIT 구문 미적용
firstResult/maxResults가 메모리 내에서 적용됨- ⚠️ 경고: 컬렉션 페치와 페이지네이션 동시 사용
원인: Hibernate의 컬렉션 페치 페이지네이션
- OneToMany, ManyToMany 관계는 조인 시 데이터 수 변경
- 메모리 내에서 페이지네이션 적용
- 대용량 데이터 처리 시 성능 문제
예시
ProductLine 3개 × 각각 Comment 7개 = 21개 DB Row
→ 모든 데이터를 메모리로 가져와 JPA가 페이지네이션 계산
→ OutOfMemoryError 발생 가능
B. 응답 시간 문제
성능 저하
- 해당 카테고리의 전체 ProductLine과 Product를 메모리에 로드
- 약 100만 건 데이터 기준: 35~40초 소요
- 사용자 입장에서는 서버 다운으로 인식
C. 2개 이상의 1:N 관계 Fetch Join 불가
MultipleBagFetchException
- 2개 이상의 1:N 관계 컬렉션 Fetch Join 시 발생
- 카테시안 곱(Cartesian Product)으로 데이터 급증
- JPA에서 의도적으로 차단
Trade-off
- N+1 쿼리 + DB 커넥션 증가
- vs
- N+1 해결 + DB 커넥션 감소
D. 해결 방안: Batch Size 설정
글로벌 설정
spring:
jpa:
properties:
hibernate:
default_batch_fetch_size: 1000
효과
- N+1 문제 해결
- 메모리 문제 방지
- 페이지네이션 정상 작동
10.6 Projection 활용
생성자 방식
- DTO에 쿼리 파라미터와 동일한 생성자 필요
@RequestParam없이 DTO로 파라미터 수신 가능
10.7 JPAQuery 분리
Content vs Count
// Content 조회
JPAQuery<Entity> contentQuery = ...
List<Entity> content = contentQuery.fetch();
// Count 조회
JPAQuery<Long> countQuery = ...
Long total = countQuery.fetchOne();
N+1 문제 해결
default_batch_fetch_size글로벌 설정 필수
10.8 Page 인터페이스 사용
PageImpl 활용
return new PageImpl<>(content, pageable, total);
11. 종합 정리
11.1 CQRS 핵심 요약
주요 개념
- Command와 Query 책임 분리
- 각 모델에 최적화된 DB 선택
- 이벤트 기반 비동기 동기화
성능 최적화
- 읽기 부하 감소: 100 → 90
- 쓰기 작업 병렬 처리
- 다중 DB 전략으로 특화된 성능
11.2 실무 적용 체크리스트
기술 스택
- Kafka / Zookeeper (또는 KRaft)
- Debezium (CDC)
- Elasticsearch (검색/필터링)
- MongoDB (문서 저장)
- Redis (캐싱)
- PostgreSQL (커맨드 모델)
개발 환경
- Docker Compose 설정
- 로컬 개발 워크플로우 정립
- 모니터링 도구 구성
코드 품질
- JPA N+1 문제 해결
- Batch Size 설정
- 단방향 연관관계 우선
- Fetch Join 신중하게 사용
11.3 운영 고려사항
모니터링
- Kafka 오프셋 지연 확인
- 쿼리 모델 동기화 시간 측정
- 응답 시간 목표: 100~200ms
장애 대응
- 이벤트 큐에 의한 장애 격리
- Dead Letter Queue 구성
- 멱등성 보장
확장성
- 파티션 전략 수립
- 컨슈머 그룹 관리
- Rolling Restart 절차